Transformer-based model演进史
Attention is all you need
ViT
DETR
Deformable DETR
DiNO
前融合
PointPainting(2021)
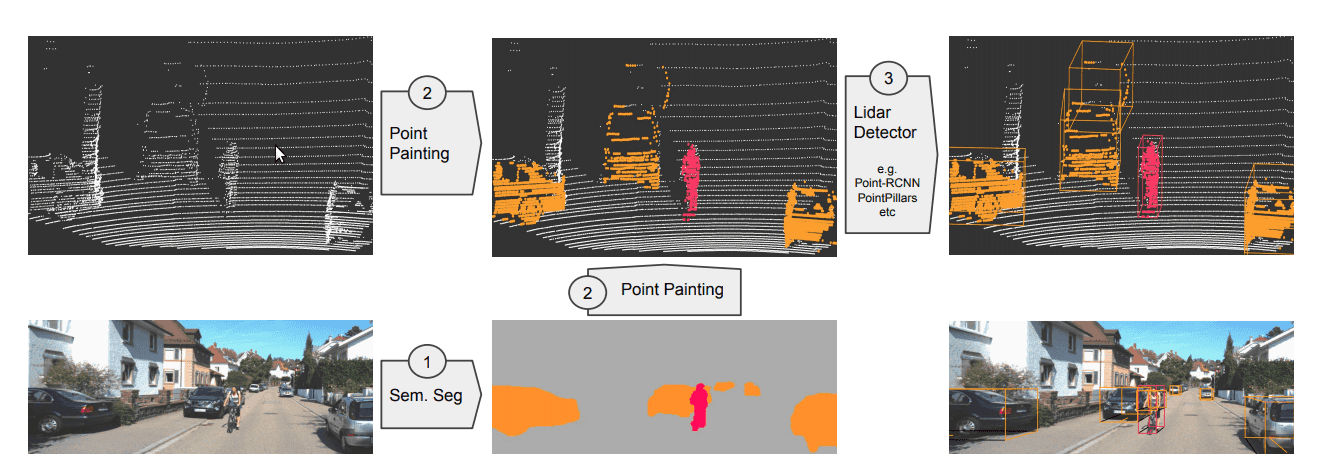
- 将 RGB 图像通过语义分割网络生成像素的语义得分向量
- 将 LiDAR 点云投影至图像平面,为每个点云赋予对应像素的语义得分向量
- 将带有融合语义的点云通过(在特征提取层增加通道维度处理语义特征的)PointPillars/VoxelNet等点云检测检测网络得到3D边界框
未作语义分割,直接将rgb图像concat到点云上并不有效,可能和rgb图像提供的信息并不那么有效

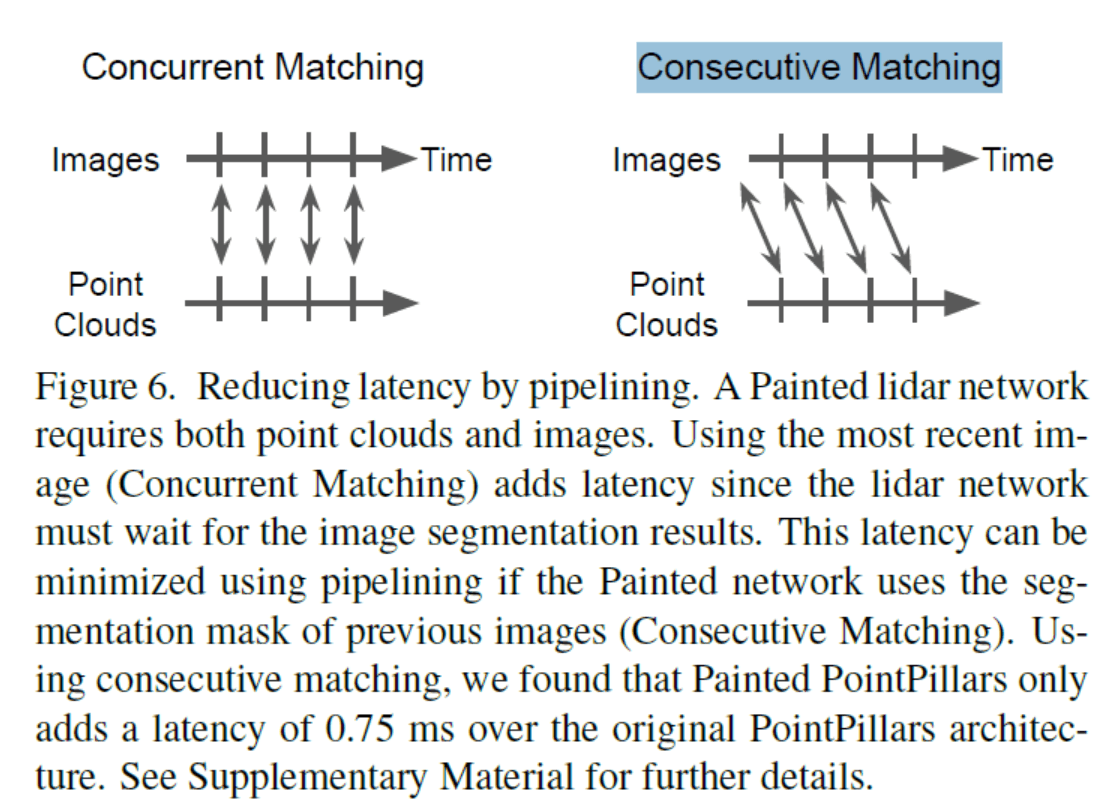
解决模态之间时间同步问题
MVP
通过2D检测结果生成虚拟点云,补充LiDAR稀疏区域的点(如远距离目标),平衡不同距离目标的点云密度。
特征融合
BEVFusion
提出Is LiDAR space the right place to perform sensor fusion?
带有transformer的特征融合
先pre-training,再fine-tuning(BERT,ViT)
attention:key-value-query, 最后输出体现query意图,在key-value对中查询相关信息得到最后输出
transfusion
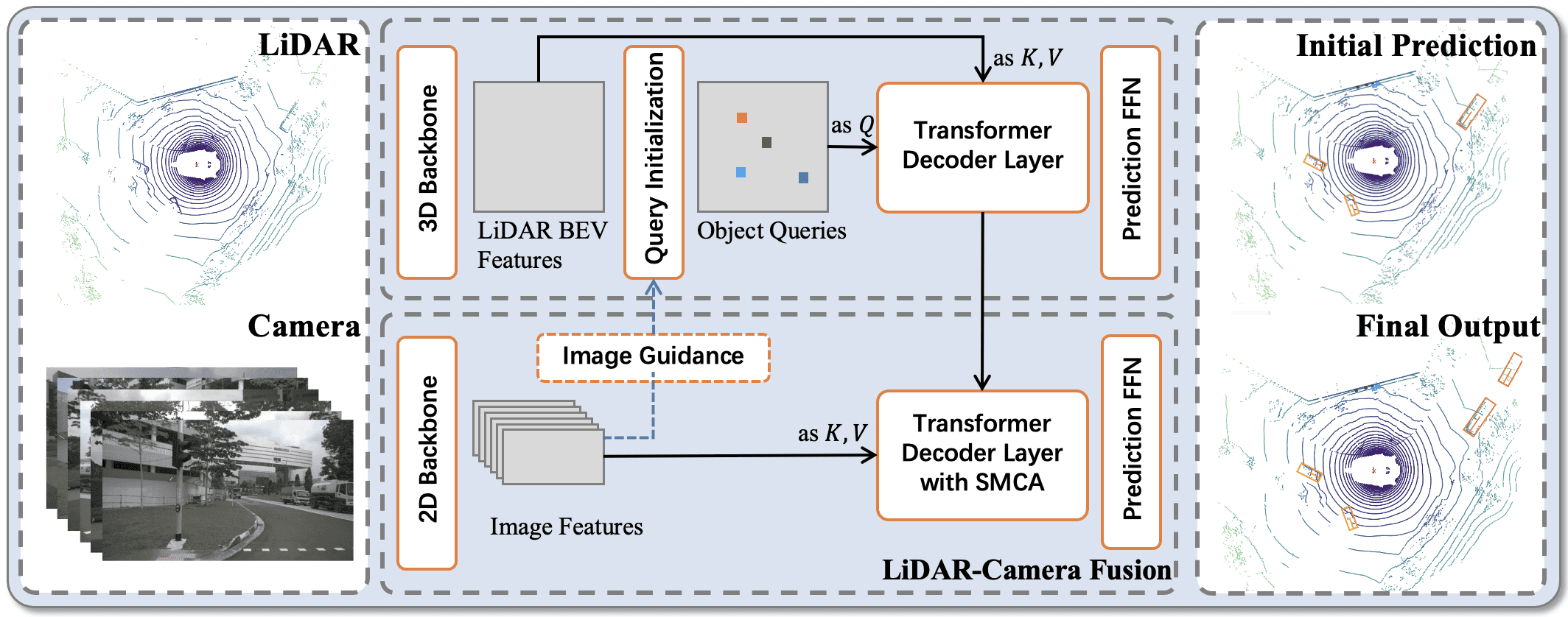
img_feature和flaaten lidar做一次attention,再根据角度和对应角度的img_feature做一次attention,然后选取其中距离在所需范围内的物体
跨模态attention后面在bevfusion4D中也有用到
fade strategy
For the fade strategy proposed by PointAugmenting(disenable the copy-and-paste augmentation for the last 5 epochs), we currently implement this strategy by manually stop training at 15 epoch and resume the training without copy-and-paste augmentation. If you find more elegant ways to implement such strategy, please let we know and we really appreciate it. The fade strategy reduces lots of false positive, improving the mAP remarkably especially for TransFusion-L while having less influence on TransFusion. https://github.com/XuyangBai/TransFusion/blob/master/configs/nuscenes.md
就是在训练的最后几个epoch不使用copy-and-paste augmentation,这样可以学习到现实中的分布,减少false positive
https://github.com/XuyangBai/TransFusion/blob/master/configs/nuscenes.md 有很多值得读的trick