pipeline搭建
基于UNet的医学图像分割
下面是分类结果,这是一个多标签分类的任务,所提供的为原始image和ground truth,prediction为网络预测的
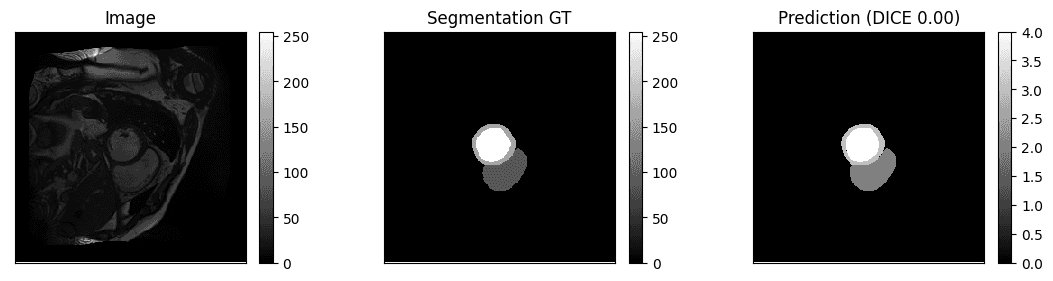
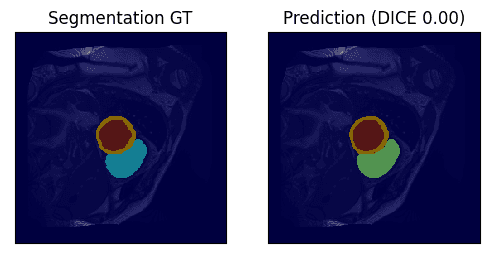
观察到所提供的ground truth为灰度图像,首先要做的便是由灰度图像转为独热编码
def convert_to_multi_labels(label):
device = label.device
B, C, H, W = label.shape
new_tensor = torch.zeros((B, 3, H, W), device=device)
mask1 = (label >= 255).squeeze(1)
mask2 = ((label >= 170) & (label < 255-1)).squeeze(1)
mask3 = ((label >= 85) & (label < 170-1)).squeeze(1)
one = torch.ones(size= (B, H, W), device=device)
zero = torch.zeros(size=(B, H, W), device=device)
new_tensor[:, 0, :, :] = torch.where(mask1, one, zero)
new_tensor[:, 1, :, :] = torch.where(mask2, one, zero)
new_tensor[:, 2, :, :] = torch.where(mask3, one, zero)
return new_tensor然后,使用UNet训练(UNet与pytorch所提供UNet源码基本一致,在此略过)
loss使用BCE loss
class MyBinaryCrossEntropy(object):
def __init__(self):
self.sigmoid = nn.Sigmoid()
self.bce = nn.BCELoss(reduction='mean')
def __call__(self, pred_seg, seg_gt):
pred_seg_probs = self.sigmoid(pred_seg)
seg_gt_probs = convert_to_multi_labels(seg_gt)
loss = self.bce(pred_seg_probs, seg_gt_probs)
return loss最后,不要忘了保存为pth模型(onnx模型更佳)
torch.save(self.model.state_dict(), save_path)rk3588板端推理部署
首先WSL配好rknn-toolkit2环境 (坑点:使用百度源)
如果前面保存的模型为pth模型,那么首先需要转换为onnx模型
import torch
from torch import nn
import torch.nn.functional as F
model_path='./model_bce.pth' #模型路径
model=UNet(n_channels=1, n_classes=3, C_base=32) #模型初始化
device = torch.device('cpu')
model.load_state_dict(torch.load(model_path,map_location=device),strict=False) #模型加载
net=model.eval()
example=torch.rand(32,1, 256, 256) #给定输入
torch.onnx.export(model,(example),'./UNet.onnx',verbose=True, opset_version=17) #导出最后的opset_version最好是19,UNet的参数要与训练时参数一致,输入要与训练时输入一致
再将onnx模型转化为rknn模型
## 测试用来构建RKNN模型的API
from rknn.api import RKNN
if __name__=="__main__":
rknn = RKNN(verbose=True,verbose_file="log.txt") # verbose为True表示打印详细的日志,verbose_file表示将日志存放到指定的路径中
# 调用config接口配置要生成的RKNN模型
# 调用config接口设置模型的预处理、量化方法等参数
rknn.config(
quantized_dtype = "asymmetric_quantized-8", # 表示默认为8位非对称量化。quantized_dtype表示量化类型 通用的模型权重和激活值都是float32类型的,会占据4个字节,而经过8位的非对称量化之后,权重和激活值量化为int8类型,只占1个字节
quantized_algorithm = "normal", # quantized_algorithm表示量化的算法,目前支持norm,mmse,kl
quantized_method = "channel", # quantized_method表示量化方式,总的有channel(通道级量化)和layer(层级量化)两种,channel的精度要要高一些,默认为channel
quant_img_RGB2BGR = False, # 表示在做量化时,是否做RGB2BGR的转换。此参数只会应用到量化阶段,并不会嵌入到RKNN模型中。
target_platform = "rk3588", # target_platform表示生成的RKNN模型要运行在哪个RKNPU平台上。通常有rk3588,rk3566,rv1126等
# target_platform="rv1126",
float_dtype = "float16", # 表示RKNN模型的浮点数的类型,目前只支持float16的格式。如果不进行量化操作,则会将原始的float32格式默认转为float16格式。
optimization_level = 3, # 表示优化等级,默认为3级,表示打开全部优化选项。如果设置为0则表示关闭所有优化选项。1,2代表中间值,表示打开部分优化选项。会对最后的精度值产生影响
custom_string = "this is my rknn model!", # 表示向RKNN模型中添加的自定义字符串信息,可以在CAPI中通过查询接口,查询到添加的自定义字符串信息
remove_weight = False, # 表示生成一个去除权重的从模型,可以使用CAPI与另一个完整的模型共享权重,从而减小内存的消耗 一般用在rv109和rv106上
compress_weight = False, # 压缩权重,可以减少模型的体积
inputs_yuv_fmt = None, # 表示RKNN模型输入数据的yuv格式
single_core_mode = False, # 表示构建的RKNN模型运行在核心模式,只适用于RK3588
)
# 添加load_xxx接口,进行常用深度学习模型的导入 将深度学习模型导入
rknn.load_onnx(
model = "./UNet.onnx", # model表示加载模型的地址
input_size_list = [[1,1,256,256]], # 表示模型输入节点对应图片的尺寸和通道数
)
# 使用build接口来构建RKNN模型
rknn.build(
do_quantization=False,
)
# 调用export_rknn接口导出RKNN模型
rknn.export_rknn(
export_path="model_bce.rknn" # 表示导出的RKNN模型路径和名称
)
rknn.release() # 释放
这里input_size_list按照自己模型情况改变,需要注意的是mean_values和std_values、rknn的预处理过程、模型量化过程并非必须,可以省略
最后,部署到开发板
将rknn模型发送到开发板上后就可以尝试运行了 重点:
- 更新驱动
- 注意pytorch相关代码不能运行,能改成numpy尽量改 极简版(不保证能运行,仅用以展示流程):
from rknnlite.api import RKNNLite
import numpy as np
if __name__ == "__main__":
rknn = RKNNLite()
rknn.load_rknn(path="resnet18.rknn")
rknn.init_runtime(
core_mask = 0,
)
output = rknn.inference(
inputs=[img],
data_format=None
)
rknn.release()完整版:
from rknnlite.api import RKNNLite
import numpy as np
from matplotlib import pyplot as plt
import math
import time
def imsshow(imgs, titles=None, num_col=5, dpi=100, cmap=None, is_colorbar=False, is_ticks=False):
'''
assume imgs's shape is (Nslice, Nx, Ny)
'''
num_imgs = len(imgs)
num_row = math.ceil(num_imgs / num_col)
fig_width = num_col * 3
if is_colorbar:
fig_width += num_col * 1.5
fig_height = num_row * 3
fig = plt.figure(dpi=dpi, figsize=(fig_width, fig_height))
for i in range(num_imgs):
ax = plt.subplot(num_row, num_col, i + 1)
im = ax.imshow(imgs[i], cmap=cmap)
if titles:
plt.title(titles[i])
if is_colorbar:
cax = fig.add_axes([ax.get_position().x1 + 0.01, ax.get_position().y0, 0.01, ax.get_position().height])
plt.colorbar(im, cax=cax)
if not is_ticks:
ax.set_xticks([])
ax.set_yticks([])
plt.show()
plt.close('all')
def process_data():
path = "./cine_seg.npz"
dataset = np.load(path, allow_pickle=True)
files = dataset.files
inputs = []
labels = []
for file in files:
inputs.append(dataset[file][0])
labels.append(dataset[file][1])
inputs = np.array(inputs)
labels = np.array(labels)
return inputs, labels
if __name__ == "__main__":
rknn = RKNNLite()
inputs, labels = process_data()
print(inputs.shape)
inputs.resize(inputs.shape[0], 1, inputs.shape[1], inputs.shape[2])
labels.resize(labels.shape[0], 1, labels.shape[1], labels.shape[2])
# 使用load_rknn接口直接加载RKNN模型
rknn.load_rknn(path="model_bce.rknn")
# 调用init_runtime接口初始化运行时环境
rknn.init_runtime(
core_mask = 0, # core_mask表示NPU的调度模式,设置为0时表示自由调度,设置为1,2,4时分别表示调度某个单核心,设置为3时表示同时调度0和1两个核心,设置为7时表示1,2,4三个核心同时调度
# targt = "rk3588"
)
# 使用Opencv读取图片
input1 = inputs[1:33]
# 调用inference接口进行推理测试
start_time = time.time()
output = rknn.inference(
inputs=[input1],
data_format=None
)
end_time = time.time()
#下面是从独热编码到图像的逻辑,可以不看
print("Execution time: {} seconds".format(end_time - start_time))
image=np.array(output)
pred_seg_probs = image[0]
pred_seg_mask = np.where(pred_seg_probs > 0.5, pred_seg_probs, np.zeros_like(pred_seg_probs))
pred_seg_mask_argmax = 3 - np.argmax(pred_seg_mask, axis=1, keepdims=True) + 1
mask = pred_seg_mask > 0
mask = np.sum(mask, axis=1, keepdims=True)
mask = mask > 0
pred_seg_mask = np.where(mask, pred_seg_mask_argmax, np.zeros_like(pred_seg_mask_argmax))
pred_seg_probs = pred_seg_mask
image = np.array(image[0, 0, :, :])
# seg_gt = self.to_numpy(seg_gt[1, 0, :, :])
pred_seg_mask = np.array(pred_seg_mask[1, 0, :, :])
set_gt = labels[1, 0, :, :]
dpi=100
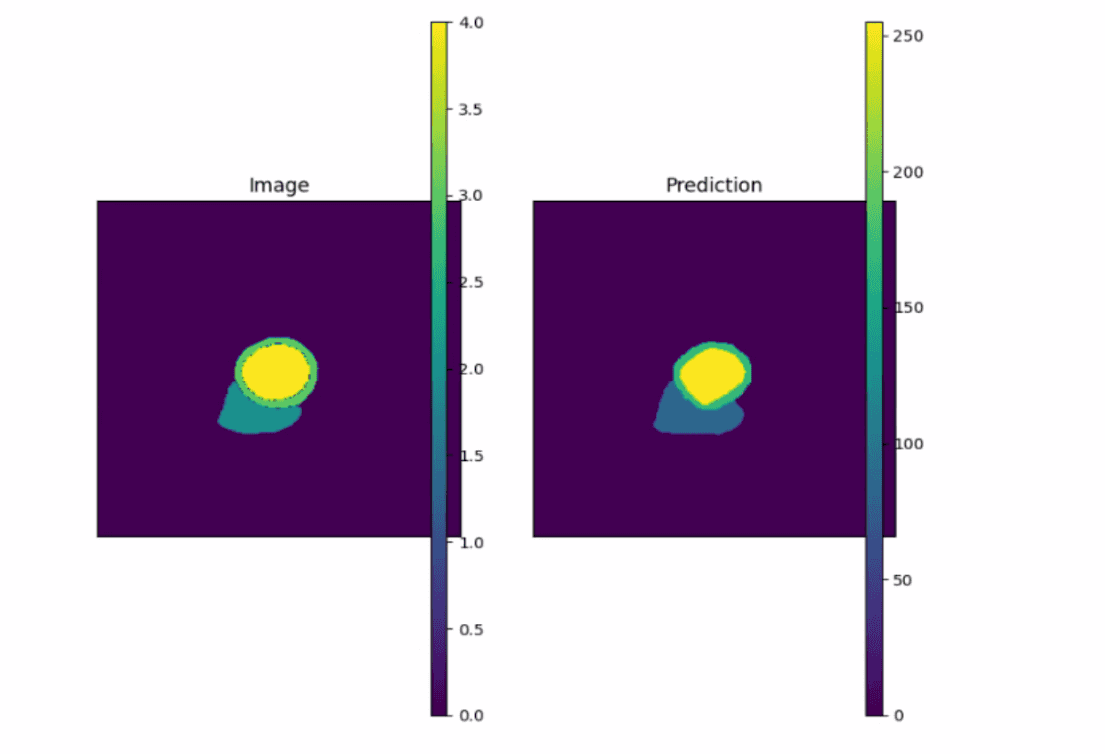
imsshow([pred_seg_mask, set_gt],
titles=['Image',
f"Prediction"],
num_col=3,
dpi=dpi,
is_colorbar=True)
rknn.release()最后结果展示
参考:
- 模型部署——使用rknn-toolkit将Pytorch模型转为RKNN模型(详细图文教程): https://blog.csdn.net/qq_40280673/article/details/136229500
- RKNN Toolkit2介绍: https://doc.embedfire.com/linux/rk356x/Ai/zh/latest/lubancat_ai/env/toolkit2.html