模型剪枝
剪枝所需工具型代码
下面是相应python代码
import torch
import torch.nn as nn
class Pruner:
def __init__(self, net, flops_reg):
self.net = net.eval()
# Initialize stuff
self.flops_reg = flops_reg
self.clear_rank()
self.clear_modules()
self.clear_cache()
# Set hooks
self.hook_handler = self._register_hooks()
def clear_rank(self):
self.ranks = {} # accumulates Taylor ranks for modules
self.flops = []
def clear_modules(self):
self.convs = []
self.BNs = []
def clear_cache(self):
self.activation_maps = []
self.gradients = []
def forward_hook_fn(self, module, input, output):
""" Stores the forward pass outputs (activation maps)"""
self.activation_maps.append(output.clone().detach())
def backward_hook_fn(self, module, grad_in, grad_out):
"""Stores the gradients wrt outputs during backprop"""
self.gradients.append(grad_out[0].clone().detach())
def _register_hooks(self):
handler_registry = []
for name, module in self.net.named_modules():
if isinstance(module, nn.Conv2d):
if name != "outc": # don't hook final conv module
handle_back = module.register_full_backward_hook(self.backward_hook_fn)
handle_forw = module.register_forward_hook(self.forward_hook_fn)
handler_registry.append(handle_back)
handler_registry.append(handle_forw)
self.convs.append(module)
if isinstance(module, nn.BatchNorm2d):
self.BNs.append(module) # save corresponding BN layer
return handler_registry
def compute_rank(self): # Compute ranks after each minibatch
self.gradients.reverse()
for layer, act in enumerate(self.activation_maps):
taylor = (act*self.gradients[layer]).mean(dim=(2, 3)).abs().mean(dim=0) # C
if layer not in self.ranks.keys(): # no such entry
self.ranks.update({layer: taylor})
else:
self.ranks[layer] = .9*self.ranks[layer] + .1*taylor # C
self.clear_cache()
def _rank_channels(self, prune_channels):
total_rank = [] # flattened ranks of each channel, all layers
channel_layers = [] # layer num for each channel
layer_channels = [] # channel num wrt layer for each channel
self.flops[:] = [x / sum(self.flops) for x in self.flops] # Normalize FLOPs
# print(self.flops, self.ranks.items())
for layer, ranks in self.ranks.items():
# Average across minibatches
taylor = ranks # C
# Layer-wise L2 normalization
taylor = taylor / torch.sqrt(torch.sum(taylor**2)) # C
total_rank.append(taylor + self.flops[layer]*self.flops_reg)
channel_layers.extend([layer]*ranks.shape[0])
layer_channels.extend(list(range(ranks.shape[0])))
channel_layers = torch.Tensor(channel_layers)
layer_channels = torch.Tensor(layer_channels)
total_rank = torch.cat(total_rank, dim=0)
# Rank
sorted_rank, sorted_indices = torch.topk(total_rank, prune_channels, largest=False)
sorted_channel_layers = channel_layers[sorted_indices]
sorted_layer_channels = layer_channels[sorted_indices]
return sorted_channel_layers, sorted_layer_channels
def pruning(self, prune_channels):
sorted_channel_layers, sorted_layer_channels = self._rank_channels(prune_channels)
inchans, outchans = self.create_indices()
for i in range(len(sorted_channel_layers)):
cl = int(sorted_channel_layers[i])
lc = int(sorted_layer_channels[i])
# These tensors are concat at a later conv2d
# res_prev = {1:16, 3:14, 5:12, 7:10}
res = True if cl in [1, 3, 5, 7] else False
# These tensors are concat with an earlier tensor at bottom.
offset = True if cl in [9, 11, 13, 15] else False
# Remove indices of pruned parameters/channels
if offset:
mapping = {9: 7, 11: 5, 13: 3, 15: 1}
top = self.convs[mapping[cl]].weight.shape[0]
try:
inchans[cl + 1].remove(top + lc) # it is searching for a -ve number to remove, but there are none
# However, the output channel of the previous layer (d4) is reduced
# So up1's input channel is larger than expected due to failed removal
except ValueError:
pass
else:
try:
inchans[cl + 1].remove(lc)
except ValueError:
pass
if res:
try:
inchans[-(cl + 2)].remove(lc)
except ValueError:
pass
try:
outchans[cl].remove(lc)
except ValueError:
pass
# Use indexing to get rid of parameters
# print(self.convs, inchans, outchans)
for i, c in enumerate(self.convs):
self.convs[i].weight.data = c.weight[outchans[i], ...][:, inchans[i], ...]
self.convs[i].bias = None
for i, bn in enumerate(self.BNs):
self.BNs[i].running_mean.data = bn.running_mean[outchans[i]]
self.BNs[i].running_var.data = bn.running_var[outchans[i]]
self.BNs[i].weight.data = bn.weight[outchans[i]]
self.BNs[i].bias = None
def create_indices(self):
chans = [(list(range(c.weight.shape[1])), list(range(c.weight.shape[0]))) for c in self.convs]
inchans, outchans = list(zip(*chans))
return inchans, outchans
def channel_save(self, path):
"""save the 22 distinct number of channels"""
chans = []
for i, c in enumerate(self.convs[1:-1]):
if (i > 8 and (i-9) % 2 == 0) or i == 0:
chans.append(c.weight.shape[1])
chans.append(c.weight.shape[0])
with open(path, 'w') as f:
for item in chans:
f.write("%s\n" % item)
def calc_flops(self):
"""Calculate flops per tensor channel. Only consider flops
of conv2d that produces said feature map
"""
# conv2d: slides*(kernel mult + kernel sum + bias)
# kernel_sum = kernel_mult - 1
# conv2d: slides*(2*kernel mult)
# batchnorm2d: 4*slides
# Remove unnecessary constants from calculation
for i, c in enumerate(self.convs[:-1]):
H, W = self.gradients[i].shape[2:]
O, I, KH, KW = c.weight.shape
self.flops.append(H*W*KH*KW*I)
return self.flops
def close(self):
for handle in self.hook_handler:
handle.remove()
return剪枝过程
下面是相应python代码,只表示所需过程,仅供读者参考
from prune_utils import Pruner
net = torch.load('./model.pth', map_location='cpu')
pruner = Pruner(net, .001)
batch_size = 32
with tqdm(total=10 * batch_size) as progress_bar:
for i, (inputs, labels) in enumerate(dataloader_train):
masks_pred = net(inputs)
loss = criterion(masks_pred, labels)
loss.backward()
pruner.compute_rank()
progress_bar.update(batch_size)
if i == 10:
break
pruner.pruning(300)
pruner.close()
torch.save(net, "pruned_model.pth")微调(fine-tune)部分
下面是相应python代码,solver中实现了模型训练所需逻辑,暂无法提供源码
net = torch.load("pruned_model.pth", map_location='cuda:0')
for name, parameters in net.named_parameters():
print(name, ':', parameters.size())
optimizer = torch.optim.Adam(net.parameters(), lr=0.001)
lr_scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer=optimizer, gamma=0.95)
solver = lab.Solver(
model=net,
optimizer=optimizer,
criterion=MyBinaryCrossEntropy(),
lr_scheduler=lr_scheduler
)
solver.train(
epochs=10,
data_loader=dataloader_train,
val_loader=dataloader_val,
save_path='./model_finetune.pth',
img_name='model_finetune',
)剪枝效果
from thop import profile
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
optimizer = torch.optim.Adam(net.parameters(), lr=0.01)
lr_scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer=optimizer, gamma=0.99)
net = torch.load("./model_finetune.pth")
net = net.to(device)
dataiter = iter(dataloader_test)
images, labels = next(dataiter)
images = images.to(device)
labels = labels.to(device)
flops, params = profile(net, inputs=(images,))
print(f'FLOPs: {flops}, Params: {params}')发现剪枝效果如下表所示
| 模型类型 | FLOPs | Params |
|---|---|---|
| 初始模型 | 250408337408.0 | 3349763.0 |
| 一次剪枝 | 188382691328.0 | 2425639.0 |
| 两次剪枝 | 147422117888.0 | 1594948.0 |
| 三次剪枝 | 105292963840.0 | 921094.0 |
但是三次剪枝并微调后效果不理想,因此使用两次剪枝的结果移植到rk3588上部署
参考
剪枝代码基于: https://github.com/pachiko/Prune_U-Net 剪枝思路基于论文: Pruning Convolutional Neural Networks for Resource Efficient Inference
部署到rk3588开发板
pth模型转化为onnx模型
import torch
from torch import nn
import torch.nn.functional as F
class DoubleConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(DoubleConv, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, 1, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, 3, 1, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.conv(x)
class Down(nn.Module):
def __init__(self, in_channels, out_channels):
super(Down, self).__init__()
self.mpconv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.mpconv(x)
class Up(nn.Module):
def __init__(self, in_channels, out_channels, bilinear=True):
super(Up, self).__init__()
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
else:
self.up = nn.ConvTranspose2d(in_channels // 2, in_channels // 2, 2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True, C_base=64):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.C_base = C_base
self.inc = DoubleConv(n_channels, C_base)
self.down1 = Down(C_base, C_base * 2)
self.down2 = Down(C_base * 2, C_base * 4)
self.down3 = Down(C_base * 4, C_base * 8)
self.down4 = Down(C_base * 8, C_base * 8)
self.up1 = Up(C_base * 16, C_base * 4, bilinear)
self.up2 = Up(C_base * 8, C_base * 2, bilinear)
self.up3 = Up(C_base * 4, C_base, bilinear)
self.up4 = Up(C_base * 2, C_base, bilinear)
self.outc = nn.Conv2d(C_base, n_classes, 1)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
x = self.outc(x)
return x
model = torch.load("model_finetune.pth", map_location="cpu")
net=model.eval()
example=torch.rand(32,1, 256, 256) #给定输入
torch.onnx.export(model,(example),'./model_finetune2.onnx',verbose=True, opset_version=17) #导出注意,虽然我们存储的是完整的模型,但是依旧需要定义原本的UNet模型,并且需要指定map_location以使得模型加载到cpu上
部署到开发板
onnx转化为rknn与在开发板上运行的代码已经在上篇文章中写得很详尽了,因而直接放效果图:
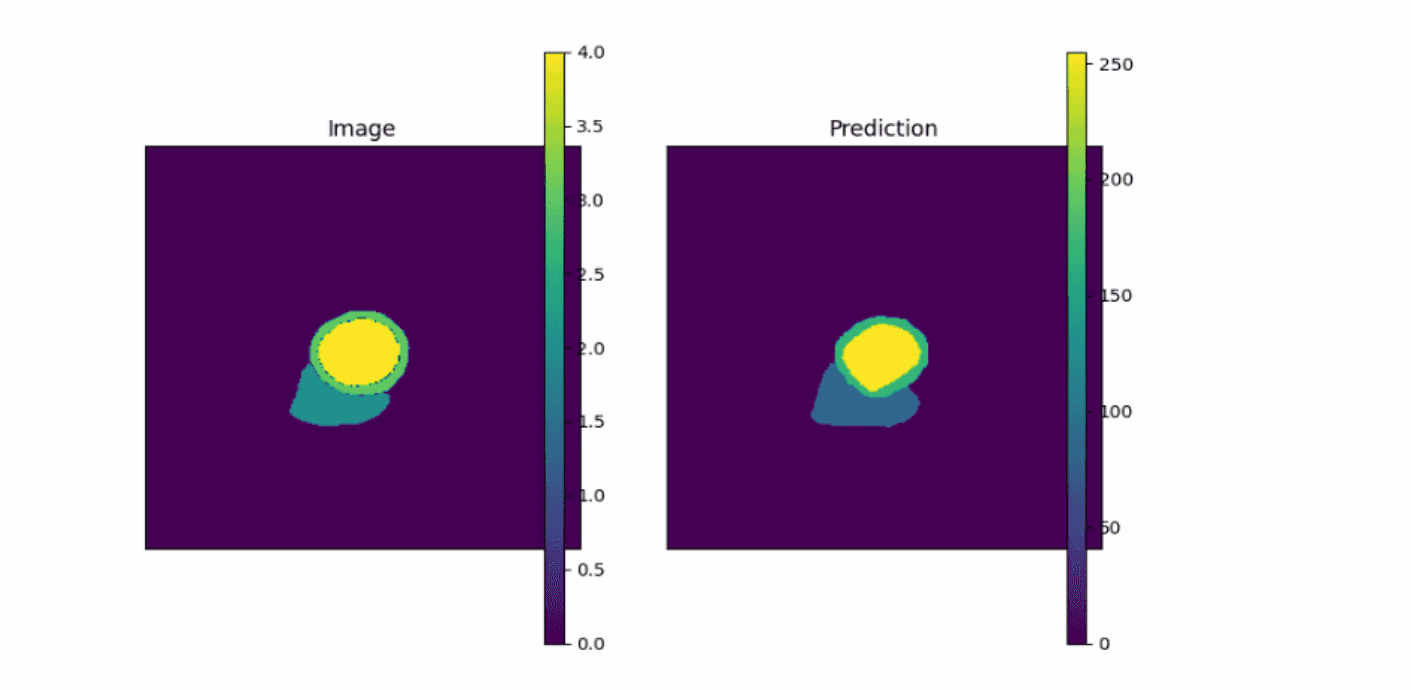
- 剪枝后
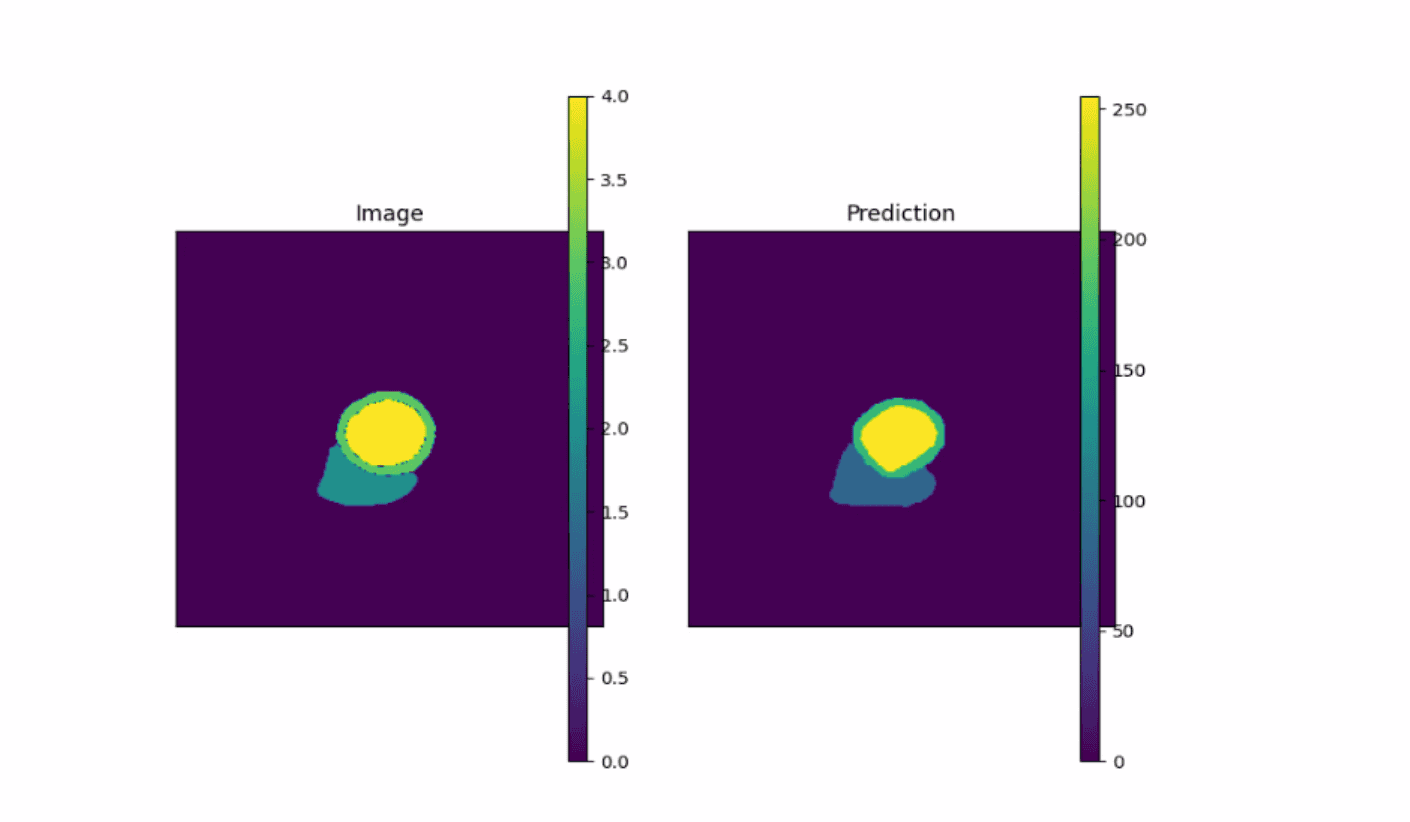
- 原模型
 运行速度及参数对比如下图:
运行速度及参数对比如下图:
| 模型类型 | FLOPs | Params | 运行速度(ms/张) |
|---|---|---|---|
| 初始模型 | 250408337408.0 | 3349763.0 | 120.7 |
| 两次剪枝 | 147422117888.0 | 1594948.0 | 81.6 |
可以观察到,虽然FLOPs降低了44%左右,但是运行速度只降低了32%左右,这是为什么呢?
观察与反思
下表是剪枝后模型各层weight的size
| 层名 | size |
|---|---|
| inc.conv.0.weight | torch.Size([32, 1, 3, 3]) |
| inc.conv.1.weight | torch.Size([32]) |
| inc.conv.3.weight | torch.Size([32, 32, 3, 3]) |
| inc.conv.4.weight | torch.Size([32]) |
| down1.mpconv.1.conv.0.weight | torch.Size([44, 32, 3, 3]) |
| down1.mpconv.1.conv.1.weight | torch.Size([44]) |
| down1.mpconv.1.conv.3.weight | torch.Size([47, 44, 3, 3]) |
| down1.mpconv.1.conv.4.weight | torch.Size([47]) |
| down2.mpconv.1.conv.0.weight | torch.Size([88, 47, 3, 3]) |
| down2.mpconv.1.conv.1.weight | torch.Size([88]) |
| down2.mpconv.1.conv.3.weight | torch.Size([70, 88, 3, 3]) |
| down2.mpconv.1.conv.4.weight | torch.Size([70]) |
| down3.mpconv.1.conv.0.weight | torch.Size([153, 70, 3, 3]) |
| down3.mpconv.1.conv.1.weight | torch.Size([153]) |
| down3.mpconv.1.conv.3.weight | torch.Size([139, 153, 3, 3]) |
| down3.mpconv.1.conv.4.weight | torch.Size([139]) |
| down4.mpconv.1.conv.0.weight | torch.Size([119, 139, 3, 3]) |
| down4.mpconv.1.conv.1.weight | torch.Size([119]) |
| down4.mpconv.1.conv.3.weight | torch.Size([92, 119, 3, 3]) |
| down4.mpconv.1.conv.4.weight | torch.Size([92]) |
| up1.conv.conv.0.weight | torch.Size([62, 231, 3, 3]) |
| up1.conv.conv.1.weight | torch.Size([62]) |
| up1.conv.conv.3.weight | torch.Size([59, 62, 3, 3]) |
| up1.conv.conv.4.weight | torch.Size([59]) |
| up2.conv.conv.0.weight | torch.Size([44, 129, 3, 3]) |
| up2.conv.conv.1.weight | torch.Size([44]) |
| up2.conv.conv.3.weight | torch.Size([41, 44, 3, 3]) |
| up2.conv.conv.4.weight | torch.Size([41]) |
| up3.conv.conv.0.weight | torch.Size([12, 88, 3, 3]) |
| up3.conv.conv.1.weight | torch.Size([12]) |
| up3.conv.conv.3.weight | torch.Size([14, 12, 3, 3]) |
| up3.conv.conv.4.weight | torch.Size([14]) |
| up4.conv.conv.0.weight | torch.Size([20, 46, 3, 3]) |
| up4.conv.conv.1.weight | torch.Size([20]) |
| up4.conv.conv.3.weight | torch.Size([16, 20, 3, 3]) |
| up4.conv.conv.4.weight | torch.Size([16]) |
可以看到,剪枝后各层size的数字呈现杂乱无序的特点,总参数量虽然降低了,但是结构相比之前不适应于硬件架构,导致运行速度降低幅度相对较小
参考
南京大学结构化剪枝综述: https://cs.nju.edu.cn/wujx/paper/Pruning_Survey_MLA21.pdf